How to Read Scientific Research Papers?
Reading research papers is not just about going through sections, it's about critically engaging with ideas, claims, and evidence. Many readers either get stuck in technical details or skip important evaluation steps. A more effective approach is to ask focused questions while reading, so you can quickly judge whether a paper is worth your time and how strong its contributions really are. When I read a paper, I try to guide myself with a few simple but powerful questions. These questions help shift reading from passive consumption to active evaluation. Over time, this approach not only saves time but also improves how we understand, critique, and build upon existing research. Give it a read !
An MPhil thesis on the average might cite around 70-100 research papers, whereas the number goes upto around ~200 for a PhD thesis. Although it depends upon the research area, and the topic of research, but according to our experience, we thoroughly read atleast half of these papers. In today's world, the race for publications and citations demands critical review/reading process to complete in no-time. A student could simply pass on the paper to an AI tool to generate the critical analysis, drawing up AI-based gaps to find solutions for them. In my opinion, it drastically creates the basis of new knowledge on AI-driven analysis which may not only be limitted, but the models might have been trained on synthetic data. The current discussion, however, doesn't intend to critic the usage of AI in the persuit of new knowledge.

How to Read Scientific Research Papers
Talking about the conventional research, the new researchers are actively engaged in reading papers. The reading process of a new researcher and a reviewer with few years of publication experience, is almost opposite. The reading target is also different, as the new researcher aims at developing understanding of a particular topic in the literature published in years, whereas the reviewer aims at assessing whether the paper could bring new knowledge to the community. New researchers, after reading dozens of paper, start reading the paper from a different section compared the reviewers. For instance, reading, and actually understanding the abstract of the paper, is foremost the difficult part for new researcher with little domain knowledge, understanding of certain terms, and limitted ability to link it with the existing literature. Contrary to this, reviewers have the ability to read the concise-form-of-text, and judge the novelty through the abstract, to determine if the paper offer new knowledge.
If you are in persuit of a MPhil or a PhD, this article helps you on how to read a research paper in early days of your research journey. The aim of reading should be to find out answers to certain questions. These questions include:
- Is this paper relevant to my topic?
- Is there a reason not to read this paper?
- What is the problem this paper is targetting?
- Which contributions or the claims are made this paper?
- Are claims justified?
- What are the conclusions?
Let us look into each of these questions in more detail, and see how could we find answers to these from a paper.
Is this paper relevant to my topic?
During the last two decades of the previous century, internet access was very limited and not widely available. Every country had a documentation center, for instance, National Technical Information Service in the United States, Iranian Research Institute for Information Science and Technology in Iran, British Library Document Supply Centre in the United Kingdom, and Pakistan Scientific and Technological Information Center in Pakistan, etc. Researchers used to go to these centers, provide their keywords or topic to them. These centers had access to internet, digital databases, libraries, and inter-library loans through out the globe. Their information professionals used to receive literature request, search the research material, collect and pass-on to the researchers after days. Although the situation has now changed a lot, but the way the articles are stored before these are read, remains almost the same. Today, most of the researchers collect research papers from the internet, keep them storing, and read when when they are free. Most of the time, researchers search various databases like Google Scholar, SCOPUS, WOS, etc, using their keywords, find out articles, download them, and build a repository to do the reading later.
The search process could result into collecting irrelevant research papers. For instance, the keywords, algorithms in the literature database, the nature of topic, and the download mechanism might result in download of a paper which appears to relevant but is actually out of scope of study. For instance, I work in 'data stream learning algorithms'. When I use these databases to search articles, it gives me many articles containing terms like 'data stream', 'classification', 'learning'. However, many of these articles are merely using multiple algorithms in a certain analysis , for instance, a medical data stream, and comparing the results. These don't contribute any new algorithm, and should not be downloaded being out of scope of my research. Since I collect articles for later reading, many times, I download irrelevant articles unknowingly. Sometimes, I don't have much time to investigate when the article title appears interesting/related, and I download them. Few times, it has happened that I was confused whether the article was relevant or not, I downloaded that thinking that I may not find it during my next search, or what happens if its relevant and I don't download it. As a result, my reposiroty often contains irrelevant material.
A similar situation may occur when a medical researcher searches the databases. If he is investigating biomakers for early detection of Alzheimer's disease, he might use terms like 'Alzheimer's', 'biomakers', or 'diagnosis'. These terms could result into many papers, however, some of them may be focusing on treatment outcomes, patient management, or biomakers for neurological disorder. Since keywords, titles, abstracts contain these terminologies, the researcher may end up downloading these for later review. Later he only finds out that these were irrelevant.
We find out that, even with the advanced access to scientific databases contrary to past, our repository might have irrelevant papers. Its important to figure out and remove these. The best way is to give a quick, one-glance review of each downloaded PDF and try to determine whether it is relevant or not. In my case, I would directly jump to the method section to see whether the paper is proposing a new algorithm. This approach may differ for other researchers. However, filtering articles at the initial stage makes it clear how many truly relevant papers you have, and whether you are left with a manageable and focused set of articles for building your knowledge base.
Is there a reason not to read this paper?
You may be wondering why one should not read a paper given that it lies in one's domain, and is highly relevant. The reason simply lies in the venue where its published. You should be very careful while selecting the papers for reading. Don't read them if these are not published in good journals or conferences.

Reading High Quality Papers is important!
Always verify the quality and credibility of a journal before reading, ensuring that it is indexed in a recognized database. If you found it even from Google Scholar, it doesn't gaurantee that it was indexed. The indexing nature could differ a lot. For instance, HEC in Pakistan has a list of recognized journals. You must published in these journals for securing a degree (the criteria depends upon the case/level/subject, etc). These journals may or may not be indexed in SCI, ESCI, etc, but are published by well-known publishers within the country. Other similar systems include Norwegian Scientific Index of Norway and Qualis of Brazil among many others. In Pakistan, jobs requiring publication is often bound to HEC-Recognized journal publications.
Many countries publish a list of black-listed journals. Although these journals are SCI-indexed, and have also have good impact factors, some countries do not allow publishing in the black-listed journals. For instance, Chinese Academy of Science publishes the black-listed journals' list every year. The black-list means that the journal may be compromised, and of low quality, and the research published there may not be valid.
Reading from low-quailty journals could make your research based upon articles/papers which are compromised. Usually, these journals don't have good peer-review process, or these may be new in the domain. So the findings in these journals might be unreliable, or unrealistic which may result in building a shaky foundation for your research.
Low quality journals might contain weak methods, and you might yourself start considering weak methodologies. For instance, a weak experimental design, small sample size, very simple data sets, lack of certain analysis components. Therefore, to build a stronger foundation for your research, you should consider reading high-quality papers that have high-standard experimenta designs, variety of datasets, and strongly validated methods through extensive analysis.
Reading indirectly effects the writing standards. A paper written with vague problem statements, unclear methodology, sub-standard critical review of existing work, biased conclusions, and overall unstructured argumentation, eventually influences your writing style. Frequent exposure to such papers should be avoided for high-quality writing.
What is the problem this paper is targetting?
The answer to this question is burried under claimed contributions, the methodology, the experiments, the conclusions, and your target is to know the tiny little problem/gap the paper is attempting to address.
Think of it like the levels of abstraction, where you start from the highest level and keep drilling down unless you reach the exact problem in the focus. For instance, a paper is written in the field of Data Stream Learning. This topic is way too broad and remains at highest level of abstraction. The next level is know the Learning Problem, i,e. Whether its classification, clustering or pattern extraction. If you are able to find the next level, you will discard the other two, as these are not the focus. Now, within the classification level (if we know that the paper talks about classification tasks), there could be Supervised, Unsuperised or SemiSupervised Classifications. Very rarely, papers may focus all of them, so you need to dig out further as at this level, we have not reached the actual problem yet. Within the selected type of classification, you need to see what is the problem attempting to address. For example, there could be class imbalance handling, noisy data handling, missing information handling, etc. At some stage, we might not be able to drill further. If we stop at this level, we may end up with a statement like: "This paper is talking about noisy data handling in semi-supervised classification in data stream learning."
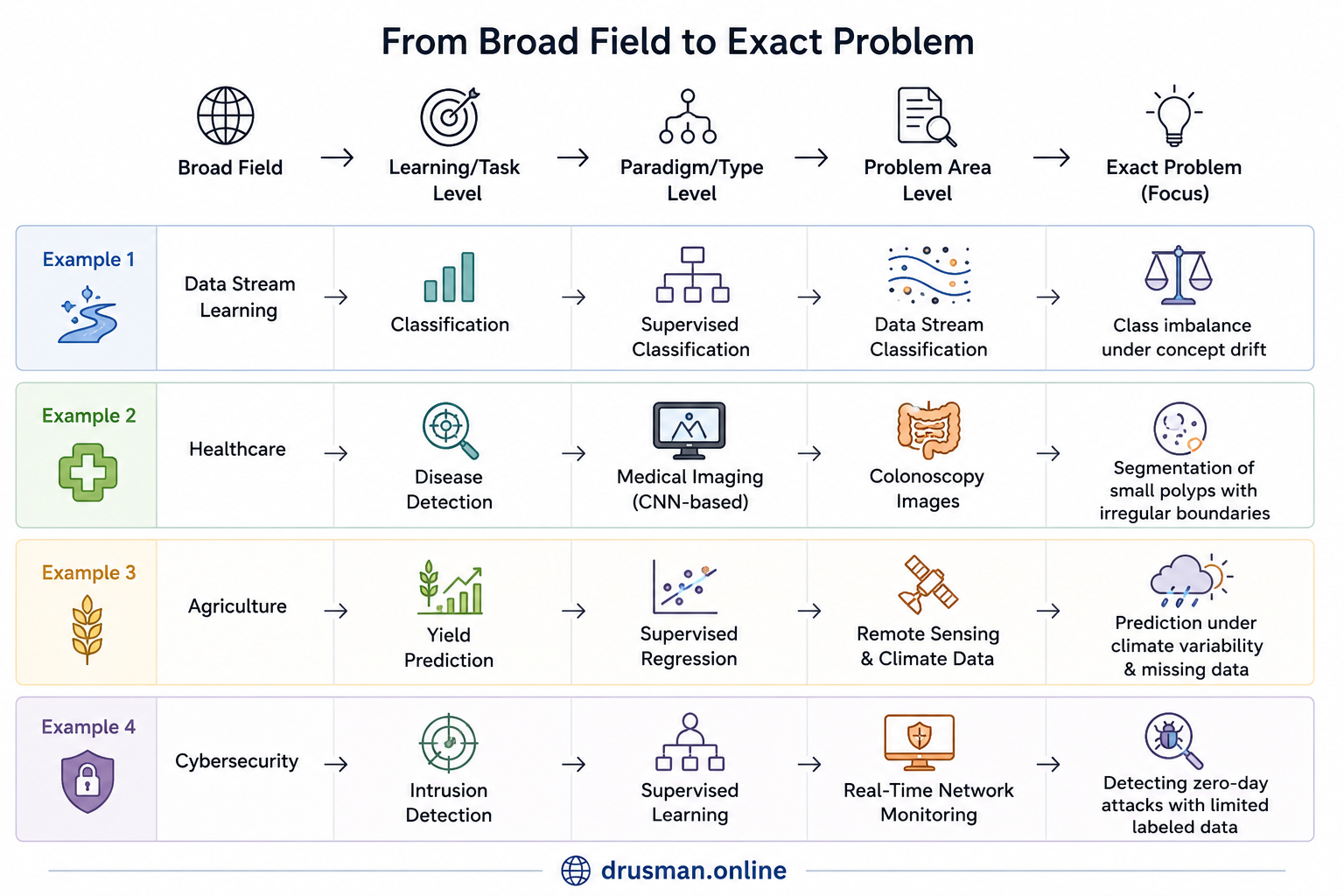
From broad field to exact problem
Another example is to drill down from Healthcare -> Medical Image -> Disease Detection -> Segmentation of polypes for early disease detection. Similarly, we can drill from Agriculture -> Crop Management -> Yield Prediction -> Prediction of yield using remote sennsing and climate data.
You may notice while you progress in the reading habit that, you can find this answer in different sections of the paper very easily. For instance, see some statements from introduction section of papers:
- However...
- Nevertheless...
- Existing methods...
- Despite significant progress...
- One major challenge...
- A limitation of current approaches...
These may lead to the actual problem this paper is attempting to address.
Another way is to read the related works section. Most papers point out the limitations of studies, for instance:
- Method A ignores missing values.
- Method B ignores concept drift.
- Method C ignores class imbalance.
The answer to you question lies in the intersection of these gaps. The current paper aims at filling these gaps, and therefore, these issues are being highlighted here.
Which contributions or the claims are made this paper?
Now, we need to dig out that given the problem identified, what are the contributions made in this paper?
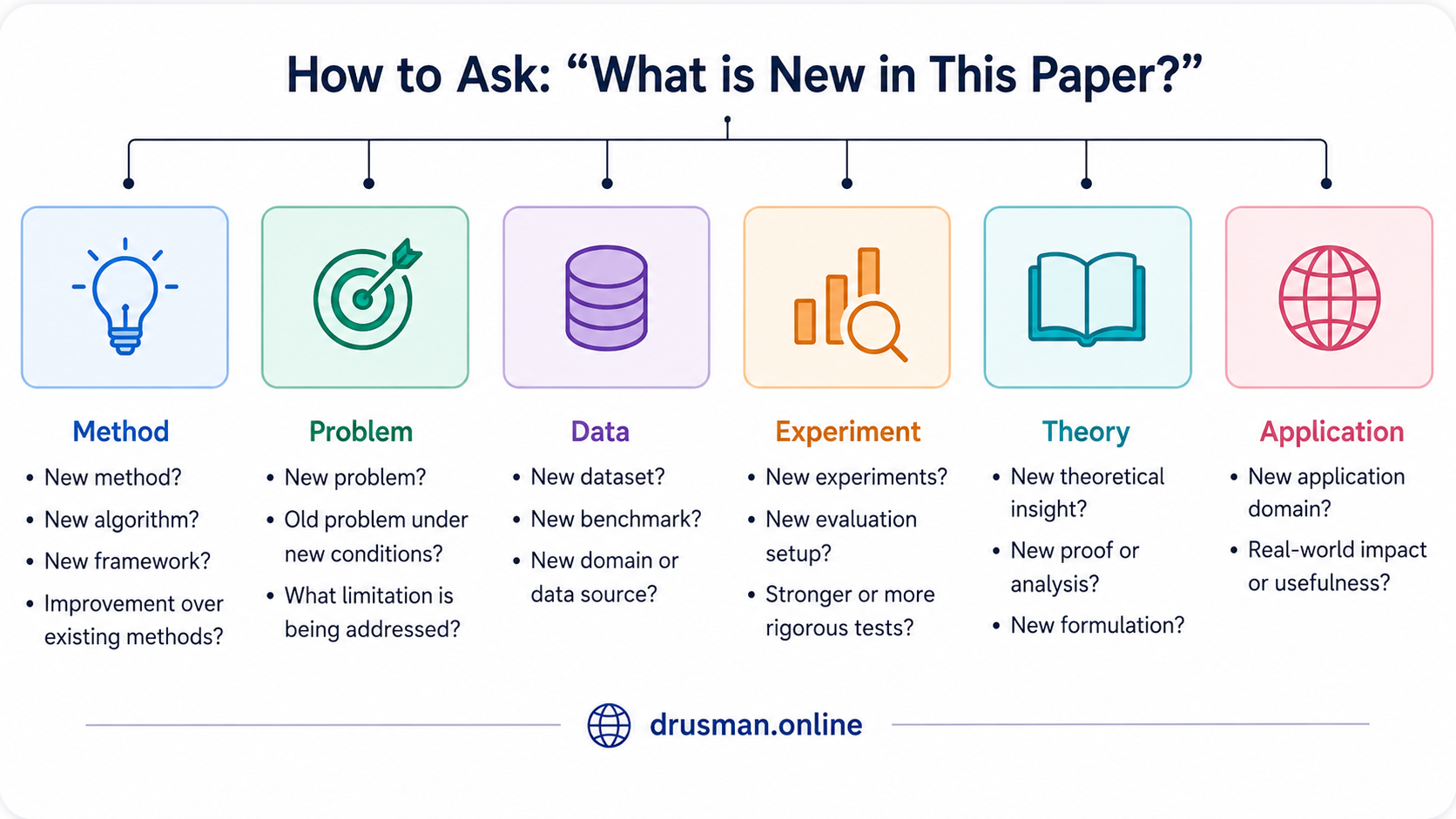
What is new in this paper?
We need to explore this through the contributions list give at the end of introduction section (most of the time). There are few lines in the abstract as well, which may not provide detailed information, but may still answer some of the questions. Thorough reading of the methodology, experiments, and discussion part, help us answer the questions below:
- What is new in this paper?
- What is the novelty/uniqueness that nobody else has talked about?
- What is the solution proposed?
- A new way to address the limitations?
- An old method is modified?
- What component differentiates it from previous methods?
- An old method is experimented with more datasets?
- A new theorey is presented?
- Is the paper solving an old problem under new conditions?
- Does it introduce a new benchmark?
- Does it study a previously unexplored domain?
- Does it collect new evidence?
- Does it compare against stronger baselines?
- Does it provide a more rigorous evaluation?
- Does it derive new proofs or guarantees?
- Does it introduce a new mathematical formulation?
Are claims justified?
This is where you critically review the paper in persuit of finding the vaccum for yourself. When you enter a classroom, you find a vacant seat to sit, in other words you need space to adjust or make room for your self. In research paradigm, you need to review the paper the same way, i.e. to know where the gaps are.
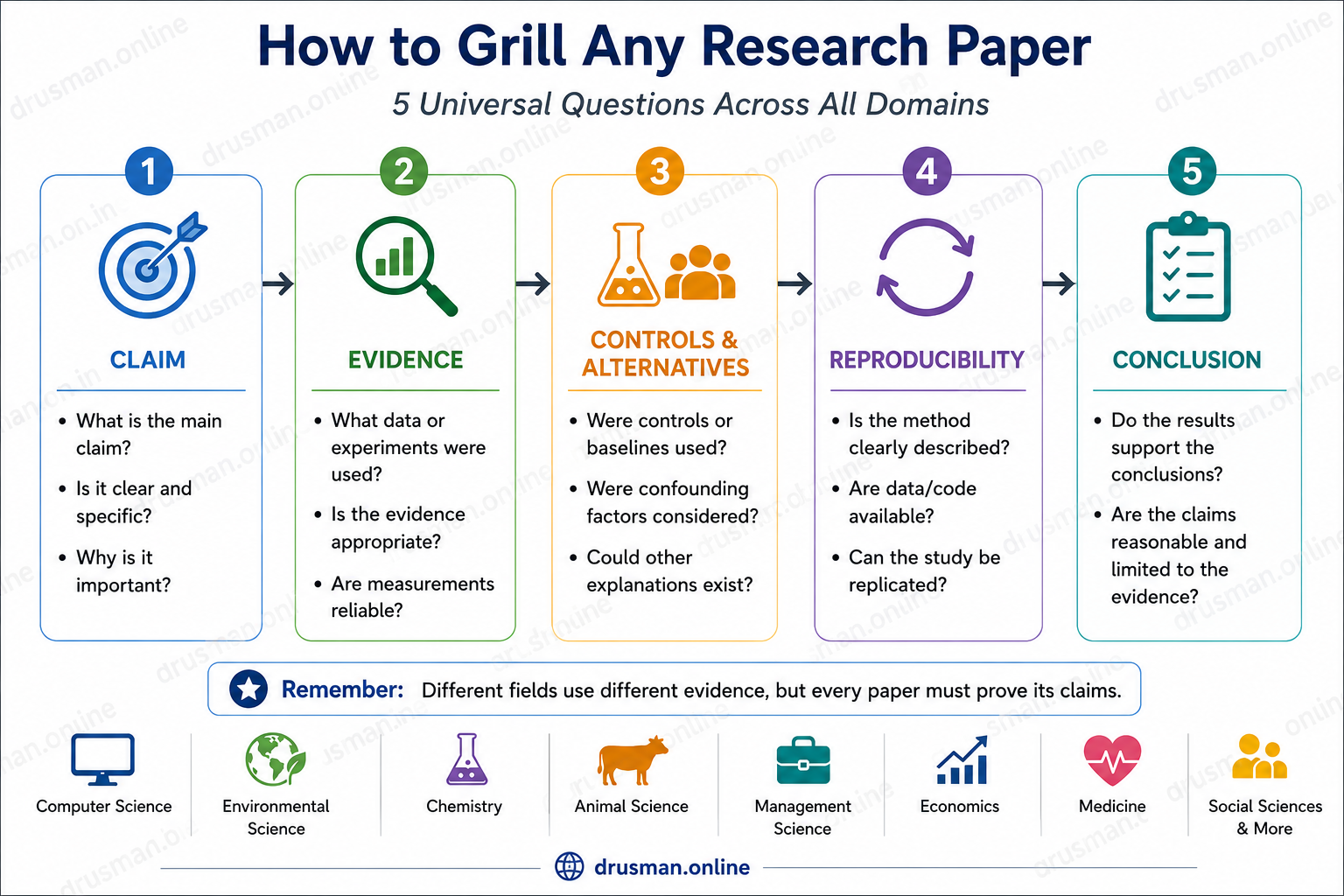
Are claims justified? How to Grill any research paper?
We might ask questions to ourselves like:
- Are the evaluations aligned with claims? If the authors claimed 3 contributions, does the paper validate all of these claims? Some times a claim might partially be validated.
- Are the datasets appropriate? It means if these are relevant to the problem, contain variety of data that may be required for validation? Another question is whether the datasets are enough? Sometimes, the paper may experiment synthetic datasets and leave out real-world datasets. An environemtal science researcher could ask if the dataset representative across locations and time?
- Another important question is the sample size/dataset size used in validation. For studies where sample size is considered an important point, the questions might be: Was the sample size sufficient? Is the sample representative? Were biases controlled? Are the survey instruments validated? Similarly, in computer science, experiments with thousands of records must be conducted to validate the method.
- Base line comparisons are also important to report in the papers, where there exist solutions already for a given problem. In such cases, one might be interested to know how this method compares with other for the same problem. We need to ask questions like: What is the method being compared against? Is it comparing Comparing only against old or weak methods.
- The metrics used in the evaluation must be suitable to the problem. For instance, the class imbalance problem must be validated against G-Mean, or F1 metric.
- Ablation experiments are also an important component for evaluation. It helps understanding what contributions are made be certain modules of a method to the overall performance. Along with Ablation experiments, parameter sensitivity are also critical to know if the performance of method/algorithm remains stable with default parameters or tuning may be required.
- Are the Results Statistically Convincing? We could ask questions like: Are multiple runs reported? Are variances reported? Are significance tests performed? For instance, A 1% improvement may be meaningless if variation is 3%. This is something you often emphasize in your own research.
- Are limitations reported? Strong papers openly discuss:When the method fails, Computational costs, Assumptions, Future improvements. Weak papers only discuss successes.
- Can the Study Be Reproduced? The research must be reproducable, so we need to digout if: Are datasets available? Are parameters reported? Is code available? Are procedures clearly described? If another researcher cannot repeat the study, confidence decreases.
So we critically review the paper with the following connected points:
Claim -> Validation -> Data -> Comparison -> Evidence -> Conclusion
What are the conclusions?
After reading a research paper, what are your takeaways? For example: What is the core problem this paper is trying to solve, and why does it matter in the broader context of the field? What are the key assumptions behind the proposed method? How strong is the evidence provided to support the claims? Do the experiments, data, or analysis truly justify the conclusions? What are the limitations or gaps that the authors may not have fully addressed, and how might these affect real-world applicability? In what ways does this work differ from or improve upon existing approaches, and is that improvement actually significant or only incremental? Finally, if I were to extend this work, what would be the most meaningful direction or missing piece to explore next?
By following these guidelines, you should be able to: read only relevant and high quality papers; find out the problem the papers are attempting to solve; the claims/contributions made by the papers; the validity of the claims; the conclusion that can be drawn on the paper.
The systematic reading is always helpful for writting a good critical review, survey paper, and finding out gaps in the literature for conducting your own research.


